# About Google Gemini Pro Vision
## Introducing Gemini AI Models
[Gemini](https://www.google.com/url?q=https://blog.google/technology/ai/google-gemini-ai/%23introducing-gemini\&sa=D\&source=editors\&ust=1702928279671913\&usg=AOvVaw3sXLHGX0QJRUSslBADx8XB) is a new AI model developed through collaboration between teams at Google, including **Google Research** and **Google DeepMind**. It was built specifically to be multimodal, meaning it can understand and work with different types of data like text, code, audio, images, and video.
Gemini is the most advanced and largest AI model developed by Google to date. It has been designed to be highly flexible so that it can operate efficiently on a wide range of systems, from data centers to mobile devices. This means that it has the potential to revolutionize the way in which businesses and developers can build and scale AI applications.
Here are three versions of the Gemini model designed for different use cases:
* **Gemini Ultra:** Largest and most advanced AI capable of performing complex tasks.
* **Gemini Pro:** A balanced model that has good performance and scalability.
* **Gemini Nano:** Most efficient for mobile devices.\
Google Gemini Pro Vision was created from the ground up to be multimodal (text, images, videos) and to scale across a wide range of tasks.
### Intended Use
Gemini Pro Vision is a Gemini large language vision model that understands input from text and visual modalities (image and video) in addition to text to generate relevant text responses.
Gemini Pro Vision is a foundation model that performs well at a variety of multimodal tasks such as visual understanding, classification, summarization, and creating content from image and video. It's adept at processing visual and text inputs such as photographs, documents, infographics, and screenshots.
### Use cases
1. Visual information seeking: Use external knowledge combined with information extracted from the input image or video to answer questions.
2. Object recognition: Answer questions related to fine-grained identification of the objects in images and videos.
3. Digital content understanding: Answer questions and extract information from visual content like infographics, charts, figures, tables, and web pages.
4. Structured content generation: Generate responses based on multimodal inputs in formats like HTML and JSON.
5. Captioning and description: Generate descriptions of images and videos with varying levels of details.
6. Reasoning: Compositionally infer new information without memorization or retrieval.
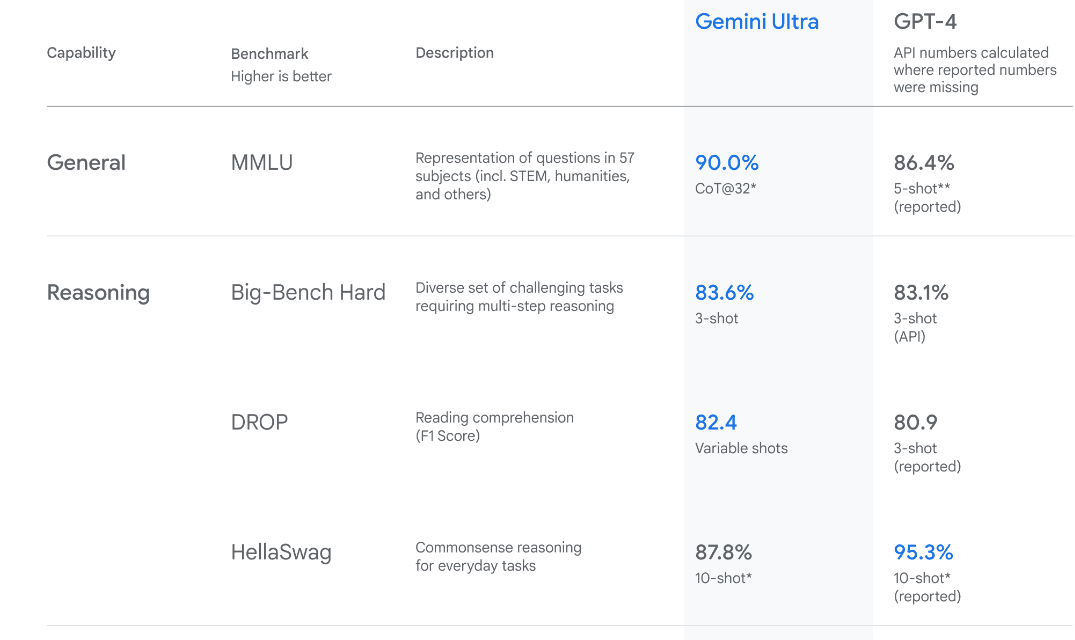
Gemini Ultra has state-of-the-art performance, exceeding the performance of GPT-4 on several metrics. It is the first model to outperform human experts on the Massive Multitask Language Understanding benchmark, which tests world knowledge and problem solving across 57 diverse subjects. This showcases its advanced understanding and problem-solving capabilities.
Know more about **Gemini.**
{% embed url="" %}